Mi segundo cerebro: cómo construí una wiki que la IA mantiene sola
La idea viene de una reflexión de Andrej Karpathy sobre el uso de LLMs. La mayoría los usa para buscar información. Yo quería algo distinto: usarlos para mantener una base de conocimiento personal que crezca y se corrija sola.
El resultado es una wiki en Markdown que la IA actualiza automáticamente cada vez que guardo un bookmark, un post de LinkedIn o una nota de voz.
La estructura del sistema
Dos carpetas. Nada más.
raw/— contenido sin procesar: bookmarks exportados, posts guardados, transcripciones de notas de voz, archivos legacywiki/— artículos en Markdown organizados por categoría, generados y mantenidos por la IA
La idea es sencilla: todo lo que entra va a raw/. La IA lo procesa, extrae lo relevante y actualiza el artículo correspondiente en wiki/. Si no existe el artículo, lo crea. Si ya existe, añade contexto o corrige lo que haya cambiado.
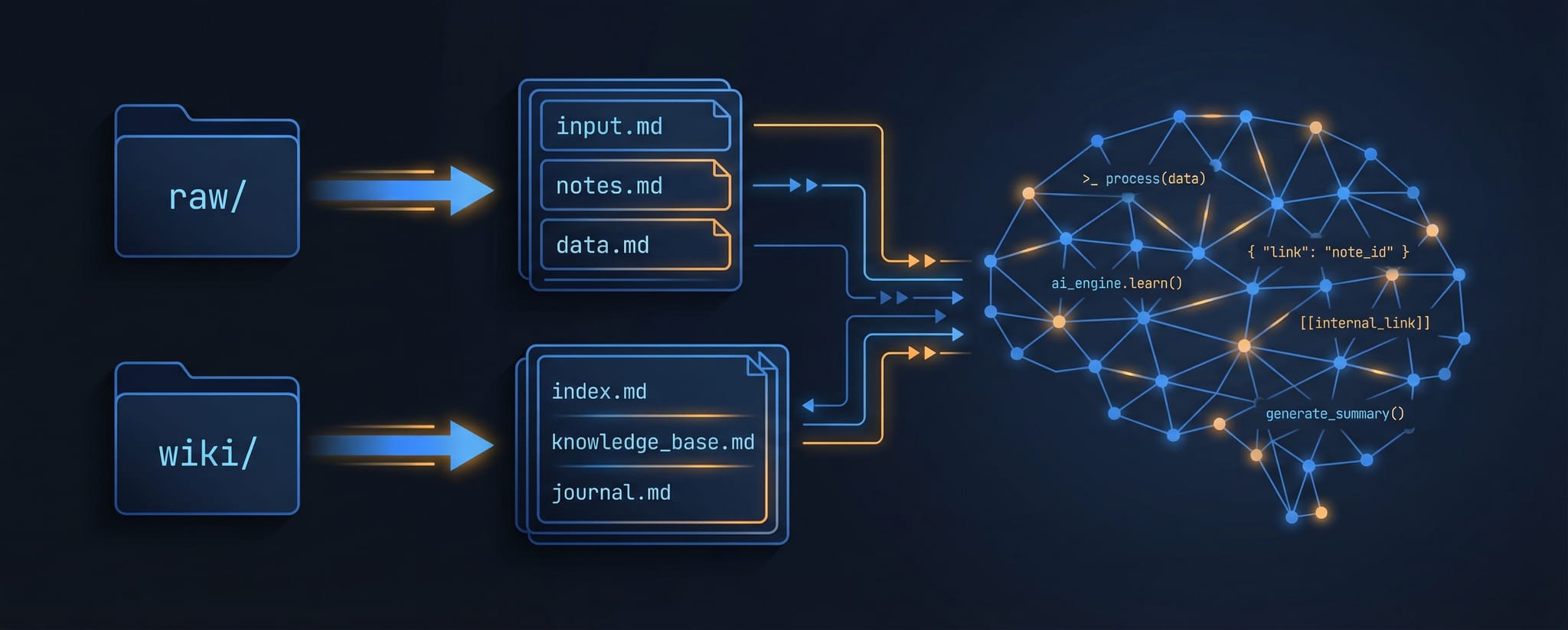
El resultado actual: 12 artículos activos cubriendo las categorías en las que me muevo profesionalmente.
Tres fuentes de ingesta
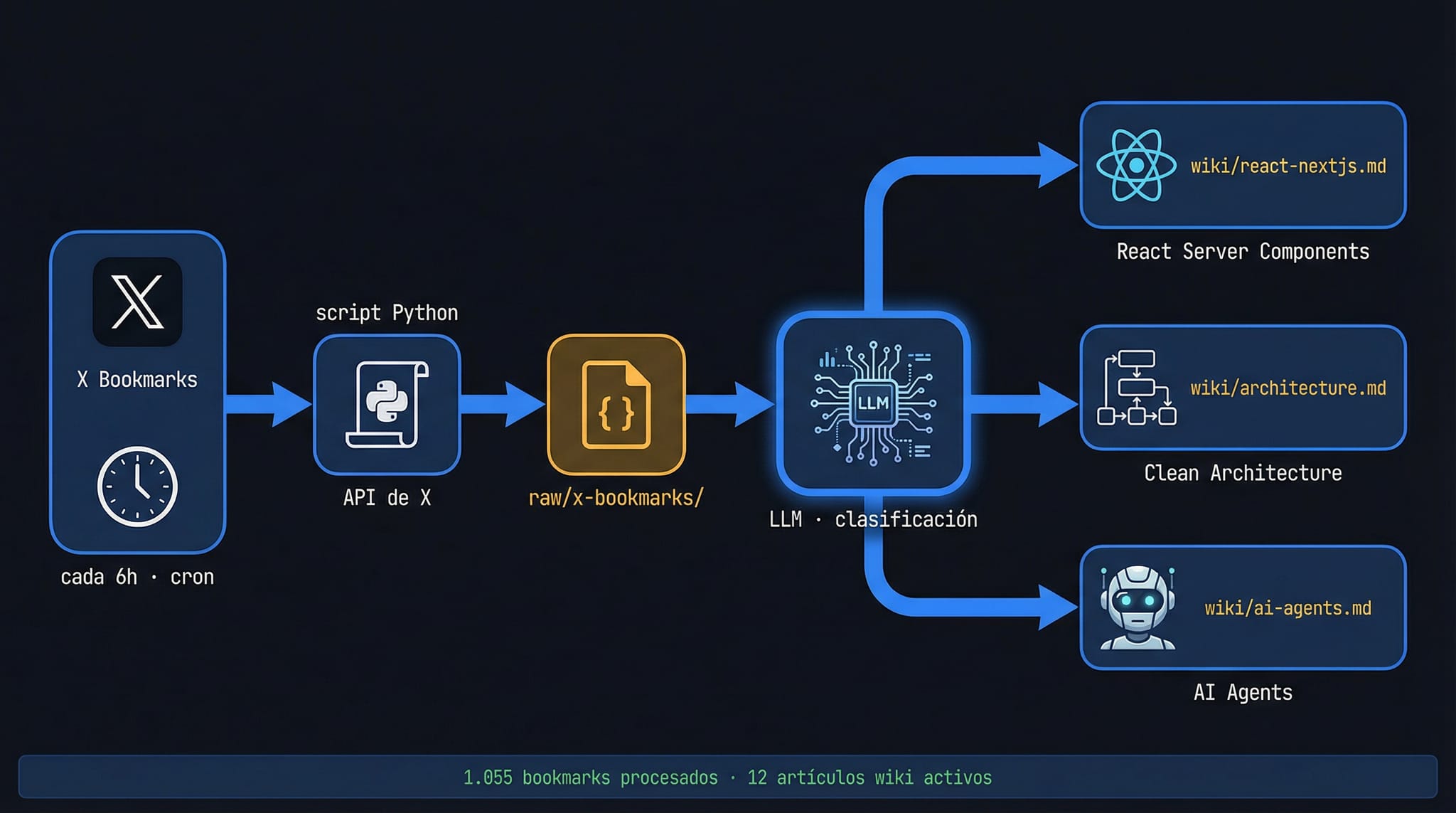
1. Bookmarks de X (cada 6 horas)
Un script Python sincroniza automáticamente mis bookmarks de X vía API. El LLM los clasifica y añade cada uno al artículo wiki correspondiente, con contexto sobre por qué ese recurso es relevante.
El resultado concreto: 1.055 bookmarks procesados en 12 artículos activos.
No es una lista de enlaces. Cada recurso tiene explicación de qué aporta y cómo se relaciona con el resto del contenido del artículo. Un bookmark sin contexto vale poco. Con contexto se vuelve útil.
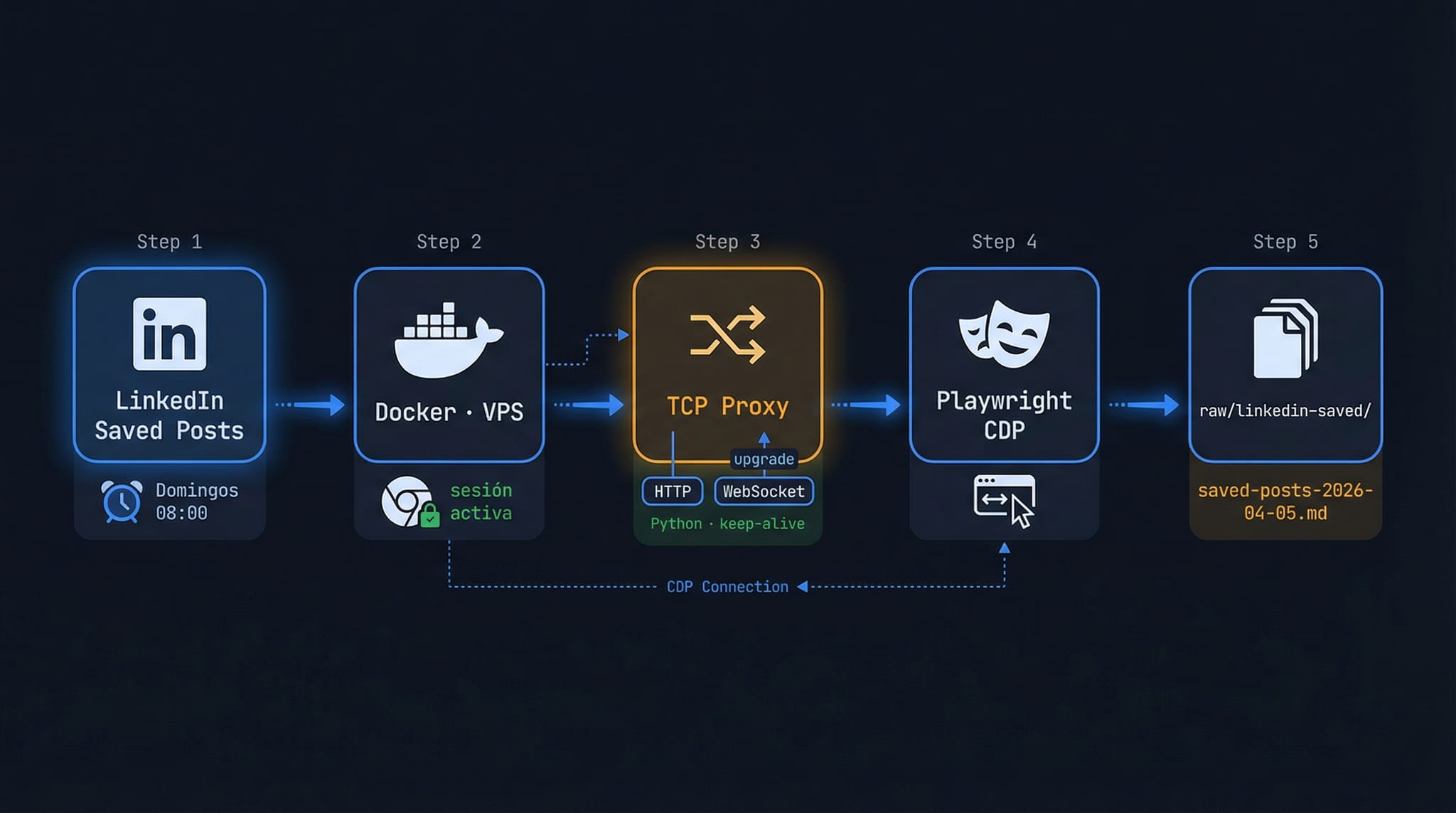
2. LinkedIn Saved Posts (cada domingo)
LinkedIn no tiene API oficial para posts guardados, así que la solución es un poco más artesanal: Docker con Chromium y Chrome DevTools Protocol. Playwright automatiza el navegador desde dentro del contenedor, extrae el contenido de una sesión autenticada, y lo pasa al pipeline de ingesta.
No es la solución más elegante, pero funciona. Y al correr en Docker, no interfiere con nada local.
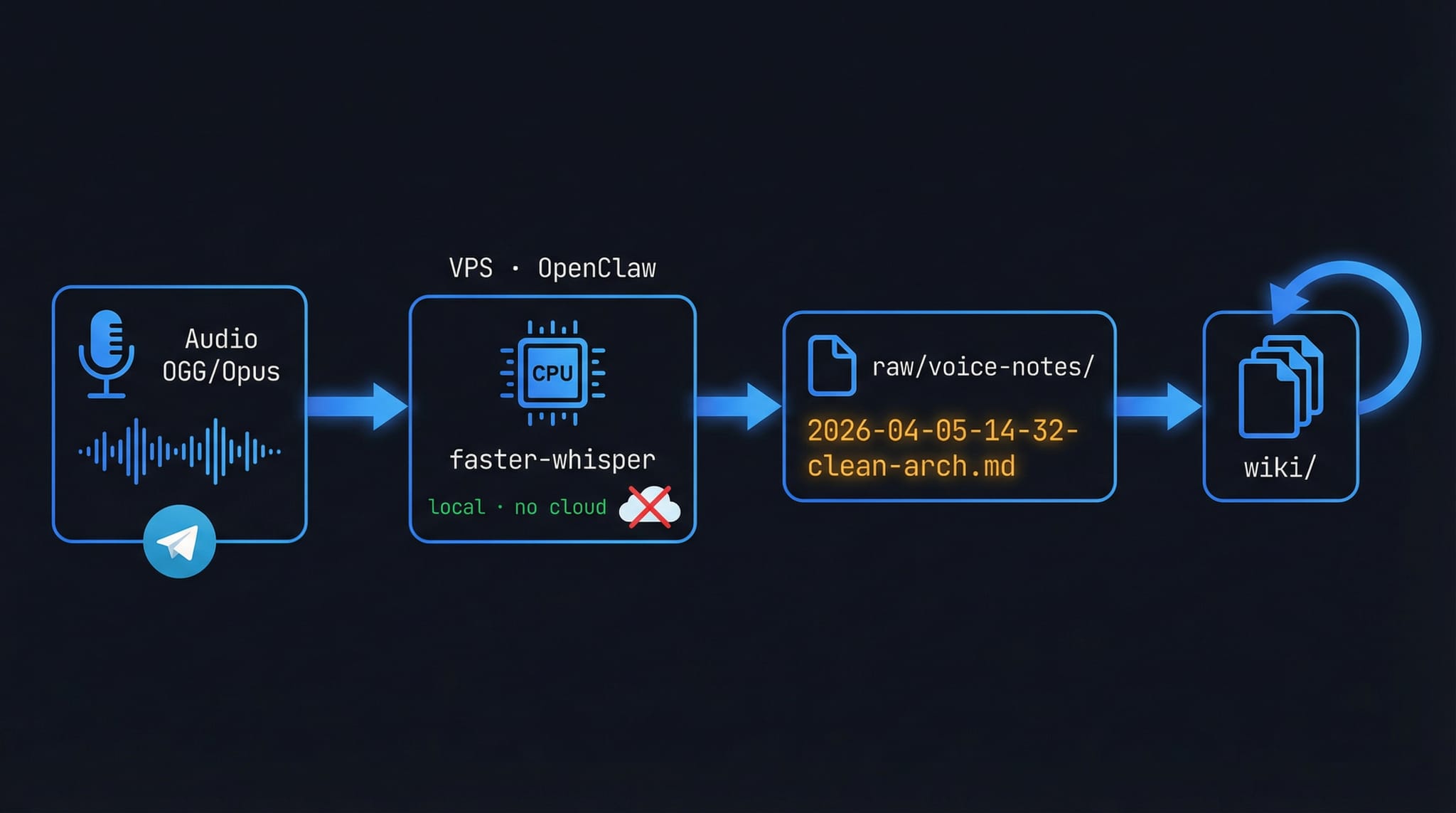
3. Notas de voz (bajo demanda)
Las notas de voz se envían por Telegram. Un agente las recibe, las transcribe localmente con faster-whisper, las categoriza y actualiza el artículo wiki correspondiente.
El flujo completo ocurre en local: sin APIs externas de transcripción, sin datos enviados a ningún servicio de terceros.
Lo que hace que el sistema no se degrade
El mayor riesgo de un sistema así es que los errores se acumulen. La IA añade algo incorrecto, nadie lo corrige, y con el tiempo la wiki está llena de afirmaciones dudosas o contenido duplicado.
Dos mecanismos automatizados evitan esto:
Health checks mensuales: un script revisa cada artículo en busca de contradicciones internas, afirmaciones sin fuente y temas mencionados recurrentemente que deberían tener artículo propio pero no lo tienen.
Linting semanal: detecta duplicados entre artículos y sugiere reorganizaciones cuando una categoría ha crecido demasiado y empieza a perder coherencia.
Ninguno de los dos corrige automáticamente. Generan un informe que yo reviso. La IA sugiere, yo decido.
El feedback loop
Hay un principio que aplico en todo el sistema: todo output generado debe propagarse de vuelta a la wiki.
Si escribo un artículo para el blog, las ideas que usé y las fuentes que consulté deben quedar reflejadas en los artículos wiki correspondientes. Si genero código con un agente, el patrón o la técnica que funcionó debe registrarse.
Los templates de trabajo incluyen un campo explícito: ¿qué artículos de la wiki se actualizaron con esto? Si no se puede responder esa pregunta, el output no está completo.
Es lo que diferencia un sistema de captura de un sistema de aprendizaje.
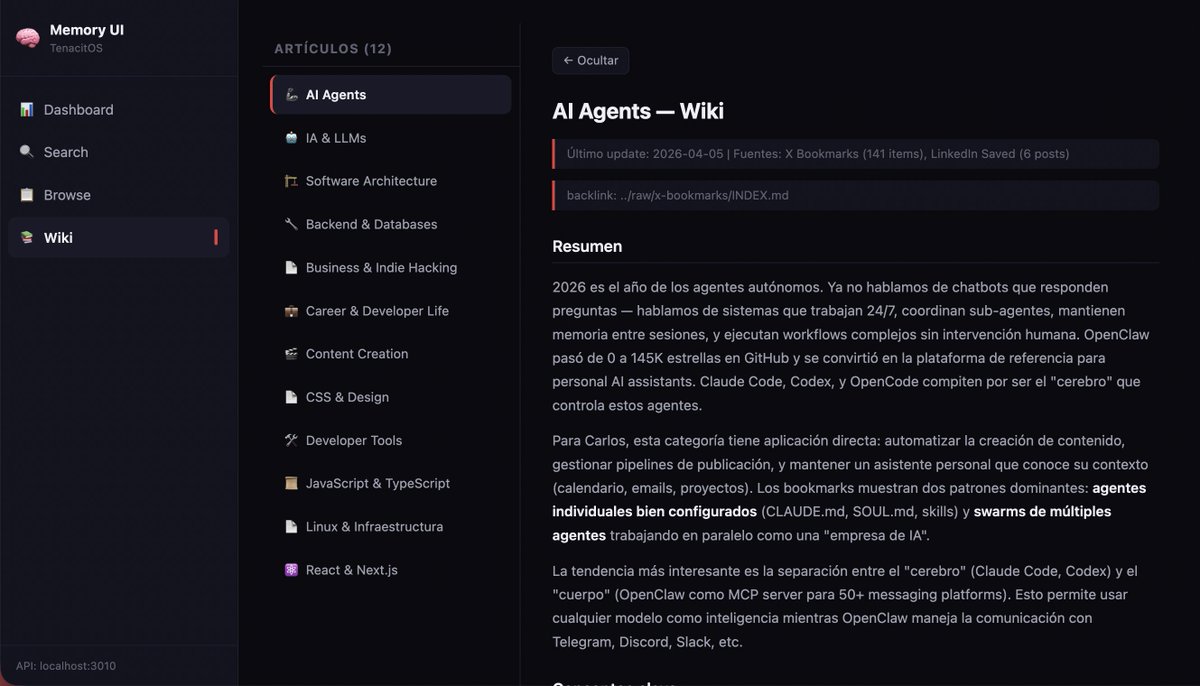
Las categorías actuales
Los 12 artículos activos cubren:
- AI & LLMs
- AI Agents
- JavaScript/TypeScript
- React & Next.js
- Backend & Databases
- Dev Tools
- Architecture
- Content Creation
- Career
- CSS & Design
- Linux/DevOps
- Business & Indie Hacking
La granularidad importa. Demasiado amplia (un solo artículo de "tecnología") genera documentos inmanejables. Demasiado específica (un artículo por librería) crea confusión y duplicados. 12 categorías es el equilibrio que funciona para mi caso de uso.
Lo que aprendí construyéndolo
La síntesis importa más que el almacenamiento. El valor no está en tener los bookmarks guardados, sino en tener el contexto de por qué ese recurso es relevante y cómo encaja con lo que ya sabes. Eso es lo que la IA añade.
La fricción de ingesta determina si el sistema se usa. Si guardar algo requiere más de un paso, no se hace. Los tres canales de entrada (bookmarks automáticos, scraping semanal, nota de voz por Telegram) están elegidos precisamente porque tienen fricción mínima.
El mantenimiento no puede ser manual. Los health checks y el linting existen porque si el sistema necesita revisión manual constante, acaba abandonado. La IA hace el trabajo de auditoría; yo solo leo el informe cuando quiero.
El sistema lleva varios meses en producción y sigue creciendo. No es perfecto, pero es el primero que realmente uso de forma consistente. Y eso, para un sistema de gestión del conocimiento, es lo único que importa.