Del Vibe Coding al Spec Driven Development: cómo dirigir agentes de IA sin perder el control
Llevo más de 15 años usando este blog como cuaderno de apuntes. Lo que empecé escribiendo sobre JavaScript y Node.js ha ido evolucionando con lo que yo evoluciono y aprendo.
Estoy cursando el Swift Agentic Engineering Program de Apple Coding Academy, el programa de Julio César Fernández. Me apunté por dos razones: aprender Swift para desarrollar apps nativas (Mac, iPhone, lo que surja) y entender de verdad la programación agéntica, que lleva meses siendo el tema de las conversaciones técnicas que tengo. No conozco a nadie mejor que Julio César para las dos cosas a la vez.
Lo que lees son mis apuntes de las clases, reescritos para el blog. Las infografías las generé con NotebookLM a partir de mis notas del curso. Basicamente lo que he intentado que fuera mi blog, un cuaderno para mí y para quien quiera leerlo.
Lo que está cambiando de verdad no es la velocidad. Es el ingeniero escribiendo la especificación y la IA produciendo el código.
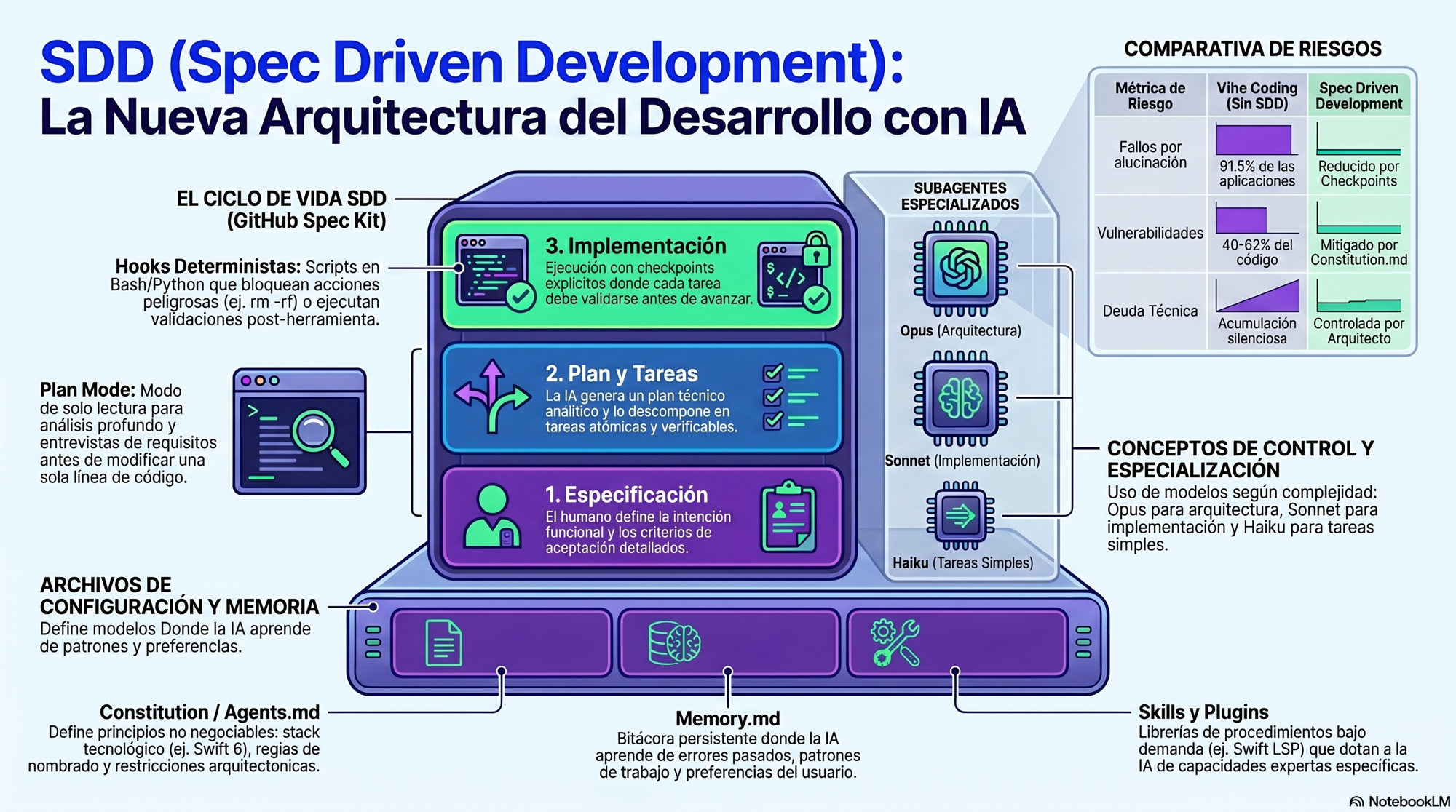
Esto es Spec Driven Development (SDD). No es lo mismo pedirle a una IA que autocomplete una función que escribir el contrato técnico completo que un agente va a ejecutar de forma autónoma. El primero te ahorra teclear, el segundo te exige pensar más, no menos.
En el SDD el código no es la fuente de verdad. La especificación si lo es, y el código es un subproducto de la especificación.
El problema del Vibe Coding
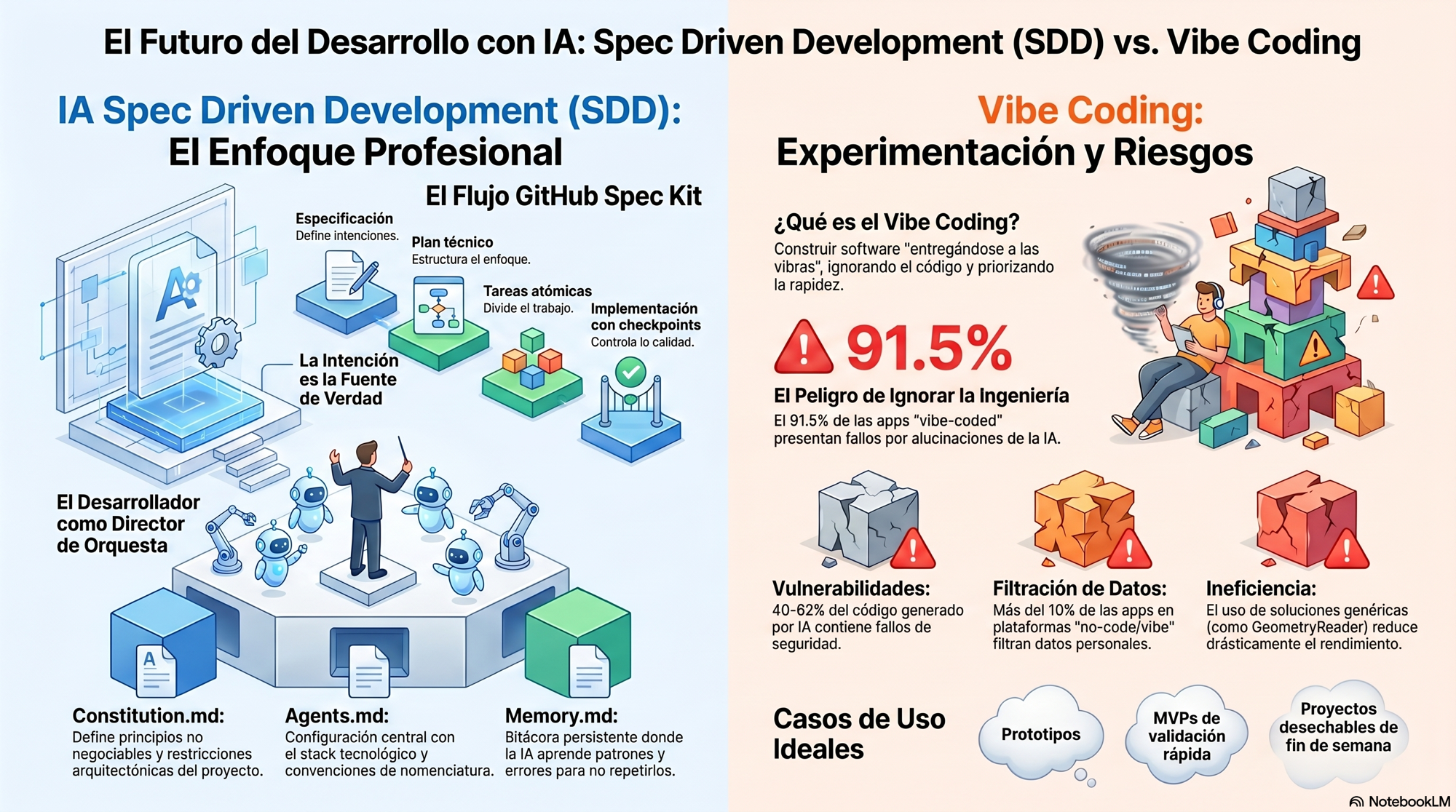
Andrej Karpathy popularizó "Vibe Coding" en febrero de 2025 para describir lo que todos hemos hecho: pedirle cosas a la IA sin entender el código que genera. Describes lo que quieres, aceptas la respuesta, y si funciona, pa'lante.
Para un prototipo funciona bien, pero en producción es otra historia.
La IA no genera código malo. Genera código coherente con los patrones que ve, y si hay una mala práctica en el contexto la replica, y si hay una configuración errónea la propaga, porque lo que hace es completar patrones. No evalúa si son correctos.
Los números son malos: entre el 40% y el 62% del código generado puramente por IA tiene fallos de seguridad (el 45% según Veracode), y el 91.5% de las aplicaciones vibe-coded tenían al menos una vulnerabilidad trazable a una alucinación del modelo (CSA Research, Q1 2026).
El caso documentado más claro es Lovable. Un análisis de 1.645 aplicaciones en la plataforma encontró que 170 (~10%) filtraban datos personales y claves de API. No fue un fallo puntual, fue una mala configuración de Supabase se replicó en cientos de proyectos porque era el patrón que la IA veía con más frecuencia en los prompts de usuarios sin experiencia en bases de datos.
El Vibe Coding no aporta criterio de ingeniería, pero es que tampoco pretendía hacerlo.
El cambio de rol: De picar a arquitecturar
La IA no crea criterio de ingeniería, solo lo amplifica. Con un contexto preciso y una especificación clara genera resultados sólidos en poco tiempo. Con un prompt vago y autonomía total genera código que compila pero falla en producción y que en unos meses nadie entiende.
El SDD formaliza justo eso. El ingeniero pasa a ser un arquitecto de orquestación cuyo trabajo es escribir la especificación con precisión, revisar el plan que propone la IA antes de que toque nada, verificar la implementación en checkpoints explícitos y detectar cuándo el agente toma un atajo que no debería. No escribe código línea a línea; escribe contratos que el agente ejecuta.
Las profesiones que emergen de aquí no son "usuarios avanzados de ChatGPT". Son Agent Architects, desarrolladores de MCPs e ingenieros de evaluación de modelos: perfiles que entienden cómo razona un modelo y cómo encadenar herramientas, no usuarios avanzados de chat.
Y hay una consecuencia que pocas veces se ve y es que trabajar con agentes te obliga a escribir mejor. La precisión al escribir una especificación importa tanto como la precisión al escribir código, más en realidad, porque el inglés se ha convertido en el idioma en que los modelos rinden mejor, y un prompt ambiguo produce exactamente lo que dice: resultados ambiguos.
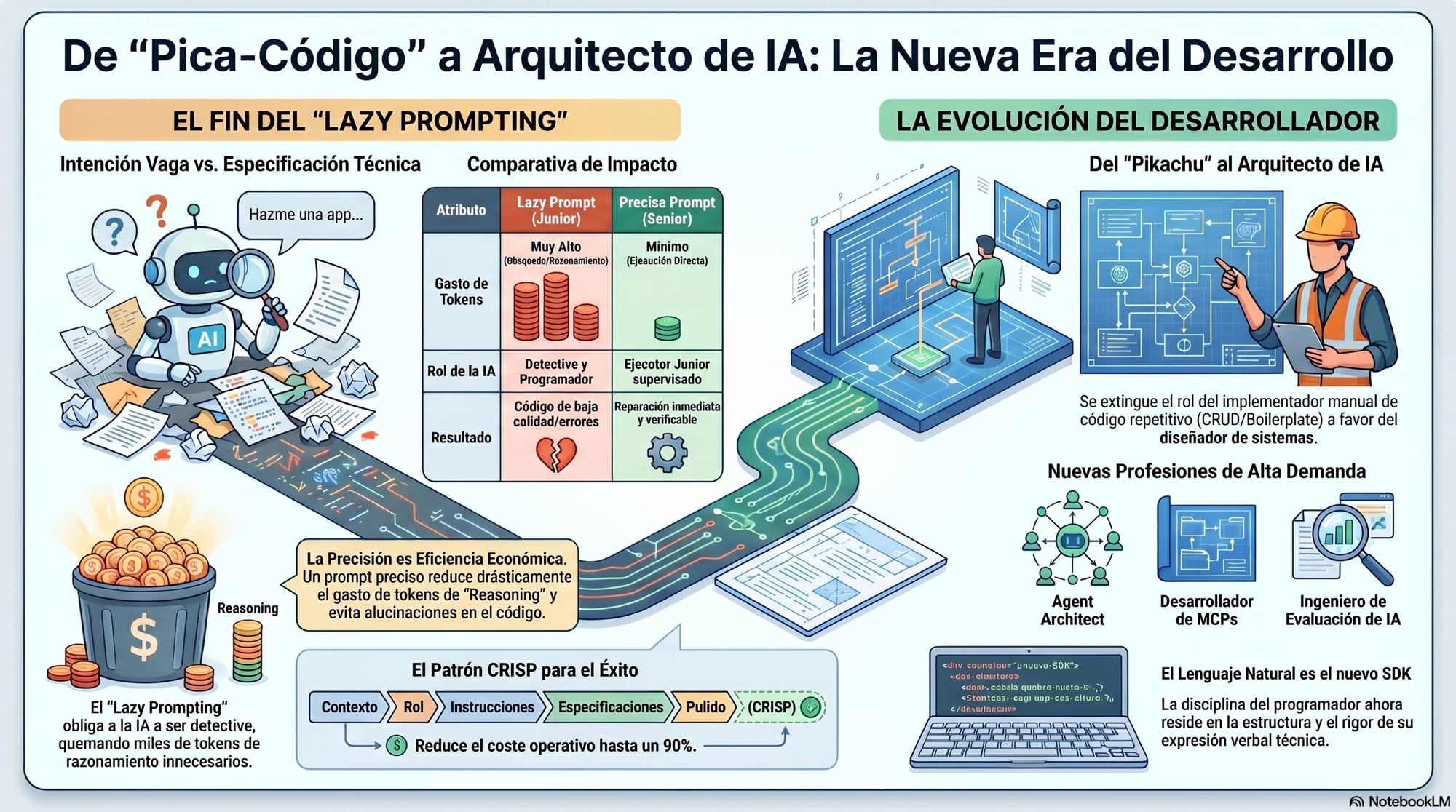
El coste real de prompts vagos: el patrón CRISP
Lanzar una intención vaga al agente, del tipo "el login no funciona, arréglalo", es una forma cara de quemar tokens de razonamiento. Un prompt impreciso obliga al modelo a explorar archivos a ciegas y reformular hipótesis hasta dar con algo útil.
El patrón CRISP existe para evitarlo:
- Context: el entorno exacto donde opera el código
- Role: la identidad que debe asumir el agente
- Instructions: qué debe hacer exactamente
- Specifications: protocolos, APIs, tipos y restricciones
- Polish/Criteria: definición de "terminado" y criterios de aceptación
La diferencia entre ambos no es solo de calidad de código, es económica. Un prompt vago puede consumir órdenes de magnitud más tokens de razonamiento que uno preciso para llegar al mismo resultado, con más errores encima.
# Prompt lazy
"El login no funciona, arréglalo."
# Prompt CRISP
"En usersViewModel.ts, el método signIn lanza un NetworkError
en la línea 140 cuando el token de refresco ha expirado.
Envuelve la llamada en un try/catch y usa el método
handleAuthError() existente en authService.ts.
No crees archivos nuevos."
Escribir bien el prompt es ingeniería de costes.
La arquitectura del entorno
Para que el SDD funcione a escala necesitas un conjunto de archivos que le den al agente contexto permanente entre sesiones, restricciones que no pueda ignorar y memoria de lo que ya ha aprendido sobre tu proyecto.
CLAUDE.md / Constitution.md — el contrato del proyecto
Es el archivo más importante: define el stack tecnológico, las convenciones de código y lo que está prohibido con ejemplos concretos de por qué.
Dos convenciones que cambian bastante el resultado:
- Escríbelo en inglés (los modelos tienen mejor cobertura de instrucciones técnicas en ese idioma)
- Usa mayúsculas categóricas,
FORBIDDEN,ALWAYS,NEVER, porque los modelos responden mejor a restricciones sin margen de interpretación. Los ejemplos concretos de lo que no quieres son más útiles que la regla abstracta; el agente los usa como referencia negativa.
No es documentación para humanos ni para el README, es el contrato que el agente tiene que cumplir antes de cualquier otra consideración.
Skills — reglas de negocio bajo demanda
Son archivos Markdown que el agente carga solo cuando los necesita. Convenciones de una tecnología, guías de auditoría, patrones propios del proyecto. Cada skill vive en su propia subcarpeta dentro de un directorio /skills en la raíz:
/skills
my-skill/
SKILL.md ← obligatorio
data.json ← opcional
another-skill/
SKILL.md
El SKILL.md lleva frontmatter YAML con nombre, descripción, reglas de invocación y herramientas permitidas. Las reglas de invocación definen cuándo se carga: puede ser un slash command (/nombre-skill) o un tipo de archivo concreto. La convención más útil que he encontrado es escribir la descripción en español para que el usuario entienda qué hace el skill, y las instrucciones técnicas en inglés, donde los modelos rinden mejor.

Separarlos del CLAUDE.md permite cargarlos con subagentes paralelos usando modelos más baratos, sin sobrecargar la sesión principal.
Memory.md — el cuaderno de bitácora
Mientras el CLAUDE.md son las reglas que tú impones, la memoria es lo que el agente aprende contigo: patrones que funcionan, errores que no hay que repetir, contexto del proyecto que sería caro reconstruir en cada sesión.
Hay un límite técnico que hay que vigilar. Cuando el Memory.md supera las 200 líneas o los 25 KB, necesita consolidación. Si no se comprime, empieza a ocupar demasiado espacio en la ventana de contexto y el agente deja de leerlo completo. La solución habitual es un subagente que lo comprime periódicamente, fusionando entradas relacionadas y descartando lo obsoleto.
Economía de tokens: el presupuesto técnico
El contexto tiene un coste real por llamada: system prompt, definiciones de herramientas (MCPs), el CLAUDE.md, los skills cargados, el historial de la sesión y tu input. Es un presupuesto que se gasta, no es gratis.
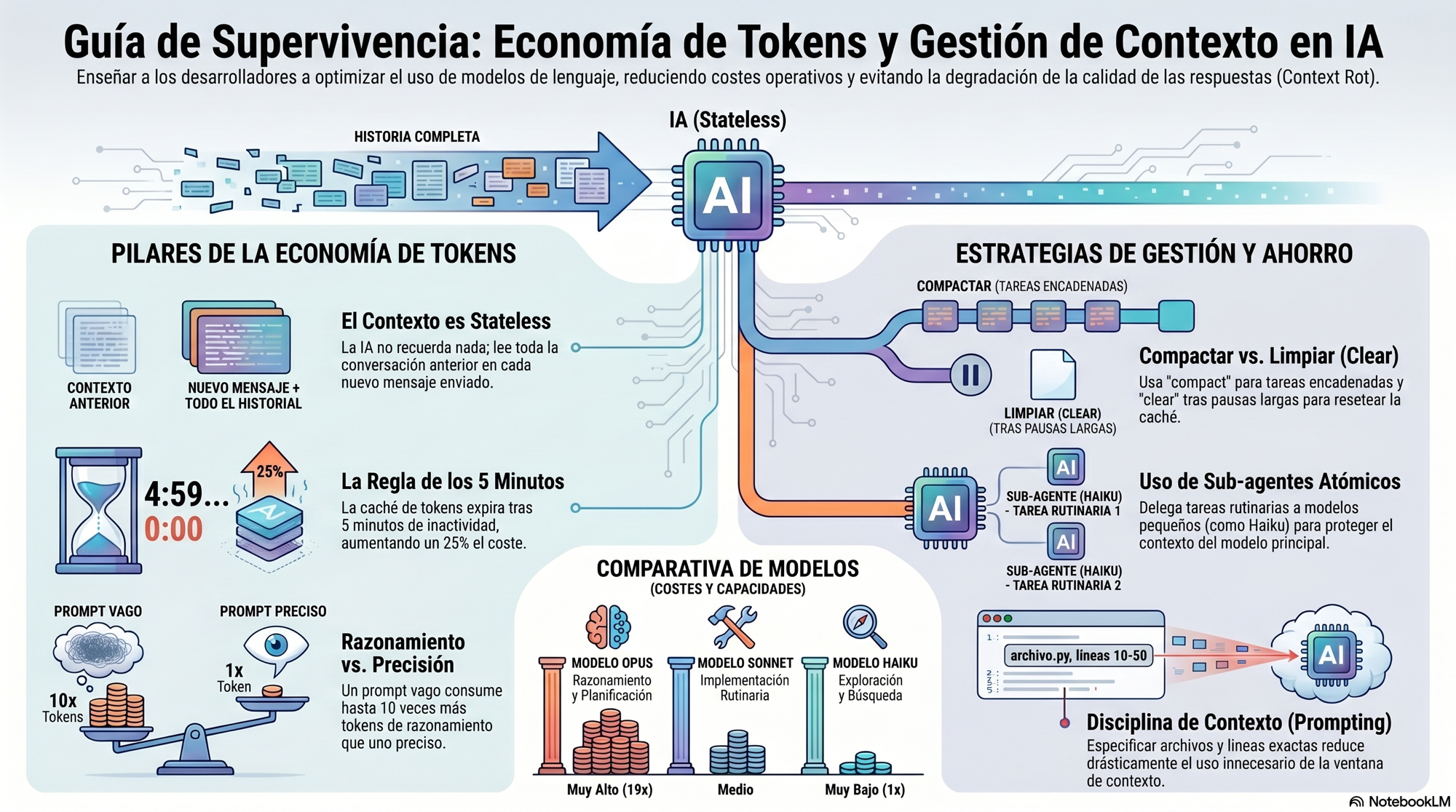
La regla de los 5 minutos
La KV Cache de tokens tiene un TTL de 5 minutos. Si dejas la sesión abierta mientras haces otra cosa y vuelves después de ese tiempo, la reconstrucción del contexto en la siguiente interacción cuesta un 25% más que si hubieras continuado sin pausar. No es un problema si pasa una vez, pero se convierte en uno cuando es tu patrón habitual.
Lo noto sobretodo con OpenClaw. Al volver a una sesión después de una pausa larga, porque me puse a hacer otra cosa, el siguiente mensaje el agente me dijo literalemente "que no recordaba nada de lo que le estaba diciendo". No es un drama si te pasa un día, pero si trabajas en sesiones cortas con interrupciones frecuentes estás pagando un overhead que no aparece como métrica.
Context Rot
La calidad de las respuestas empieza a degradar cuando el contexto alcanza entre el 20% y el 40% de su capacidad máxima, y al superar los 150k-200k tokens el agente empieza a ignorar partes de la Constitution.md (o el AGENTS/CLAUDE) porque no puede mantener todo en ventana activa.
Hay dos comandos para gestionarlo:
/compact: resume las tareas terminadas y libera presupuesto sin perder contexto relevante. Va bien al acabar un bloque de trabajo./clear: reinicia la sesión por completo. Úsalo tras pausas largas o cuando cambias de tarea radicalmente.
Sin esto el agente da vueltas, olvida restricciones que ya leyó, y se paga en cada iteración.
Orquestación de modelos
Uno de los cambios de mentalidad más útiles al trabajar con agentes es dejar de usar el mismo modelo para todo.
| Tarea | Modelo |
|---|---|
| Razonamiento, planificación, arquitectura | Opus (caro, potente) |
| Implementación rutinaria, búsqueda | Sonnet (equilibrado) |
| Tareas simples, subagentes atómicos | Haiku (barato, rápido) |
Opus es unas 19 veces más caro que Haiku. Delegar la ejecución rutinaria en subagentes Haiku mientras reservas Opus para las decisiones de arquitectura recorta factura sin perder calidad.
Anthropic tiene en research preview algo que llaman "Dreaming". Los agentes revisan el trabajo realizado entre sesiones, detectan patrones y actualizan el Memory.md mientras el usuario no está. Algo parecido a lo que hace nuestro cerebro cuando dormimos. Aún no está en producción general, pero apunta a dónde va la gestión de contexto a largo plazo.
Control de ejecución: Plan Mode y Hooks
La parte que más se subestima al empezar con agentes es el control de ejecución. Un agente con autonomía total y permisos amplios puede hacer cosas destructivas sin mala intención: borrar archivos, ejecutar rm -rf en el directorio equivocado o modificar configuraciones que nadie le pidió que tocara.
Plan Mode
Antes de que el agente modifique una sola línea de código, activas el Plan Mode. En este modo solo lee: investiga el código, entiende el contexto y genera un plan estructurado sin tocar nada.
Esto te da lo más valioso del ciclo: una revisión humana antes de la implementación. Ves qué va a hacer, detectas decisiones cuestionables y ajustas la especificación antes de que el agente empiece. También aísla los gastos de tokens, porque la fase de planificación se paga por separado de la implementación.
Hooks
Son scripts en Bash o Python que se ejecutan al margen del modelo de lenguaje y que el agente no puede ignorar ni razonar para esquivar. Un hook PreToolUse puede bloquear comandos destructivos antes de que se ejecuten, o impedir que el agente lea archivos sensibles como .env. Un hook PostToolUse puede obligar a pasar un linter antes de que el agente dé la tarea por terminada.
Plan Mode y Hooks juntos crean guardrails programáticos reales. El agente actúa dentro de los límites que defines; fuera de ellos, no puede actuar.
Seguridad
La seguridad en sistemas agénticos tiene vectores de ataque que no existen en el software tradicional.

Prompt injection
El prompt injection es la vulnerabilidad #1 en el OWASP Top 10 para LLMs 2025 y afecta al 94% de los agentes evaluados en auditorías de seguridad. El problema de fondo es que un modelo de lenguaje no distingue entre instrucciones del sistema y datos maliciosos. Si un PDF que el agente procesa contiene instrucciones ocultas en texto blanco sobre fondo blanco, las leerá y puede obedecerlas. Un agente con acceso a datos reales y herramientas con efectos en el mundo tiene una superficie de ataque que ninguna revisión manual cubre por completo.
La Trifuerza Letal
El riesgo de exfiltración se materializa cuando un agente tiene acceso a datos privados, está expuesto a contenido externo no controlado (un PDF, un email, una web con instrucciones ocultas) y además puede comunicarse hacia fuera llamando a APIs o enviando datos. Con ese triángulo completo activo, un prompt injection puede convertirse en exfiltración en una sola sesión.
Supply chain attacks
Gartner estimó que el 45% de las organizaciones sufrirían ataques a la cadena de suministro en 2025, predicción la cual se cumplió. En el contexto de agentes, instalar un servidor MCP o plugin de terceros sin auditarlo es darle al agente acceso a instrucciones que no controlas. un MCP malicioso no necesita explotar ningún fallo clásico de seguridad, basta con que devuelva instrucciones ocultas en sus respuestas y el agente las siga.
Audita el código fuente de cualquier MCP de terceros antes de instalarlo.
Mitigaciones concretas
Tres que funcionan en la práctica:
- Sanitización de entrada: elimina caracteres de control (
<,>) del contenido que el agente va a procesar para cortar la inyección más común. - Prioridad del system prompt: configura las instrucciones del sistema para que tengan precedencia explícita sobre las del usuario.
- Respuestas tipadas: fuerza al agente a responder instanciando estructuras de datos con esquemas fijos en lugar de texto libre. Apple implementó exactamente este patrón con la macro
@Generableen su Foundation Model Framework: el modelo instancia structs de Swift que el compilador puede validar, en lugar de generar texto libre que cualquiera puede contaminar.
El ciclo completo en la práctica
El flujo del GitHub Spec Kit tiene cuatro momentos:
1. Especificación: El humano define qué se construye: la función exacta, los tipos, las restricciones y los criterios de aceptación. No "haz un login"; el contrato completo de lo que debe hacer.
2. Plan técnico: El agente (en Plan Mode) analiza el código existente y genera un análisis detallado del cómo. El humano lo revisa y aprueba antes de continuar. Este es el paso que más se salta en la práctica, y el que más deuda técnica evita: ver el plan antes de que el agente toque nada es la única oportunidad real de corregir una decisión arquitectónica sin pagar el coste de deshacerla después.
3. Tareas atómicas: El plan se descompone en unidades pequeñas y verificables, cada una con criterio de aceptación propio.
4. Implementación con checkpoints: El agente ejecuta tarea a tarea. Los hooks garantizan que no se salte validaciones y el humano revisa los diffs antes de aprobar cada bloque.
Este ciclo tarda más por iteración que el Vibe Coding. Lo que recorta es el tiempo de depuración posterior y la deuda técnica que se acumula cuando nadie revisa el plan.
Por qué esto requiere ingenieros cualificados
El SDD no sirve para que gente sin conocimientos técnicos construya software de producción. Funciona exactamente al revés.
Cuando la IA propone una arquitectura que parece razonable pero es ineficiente para el caso concreto, necesitas el criterio para detectarlo. Cuando toma un atajo que no es obvio en el código pero que va a complicar el mantenimiento en seis meses, necesitas reconocerlo. Si ese criterio no está ahí, la IA lo amplifica igualmente y el resultado es código frágil que cuesta más mantener que reescribir. Menos tiempo escribiendo código línea a línea, más tiempo diseñando contratos y revisando planes.
La IA es como un experto en setas que te dice con seguridad cuáles son comestibles, y si se equivoca, se disculpa después. El criterio humano sigue siendo el único filtro.
El Vibe Coding va a seguir siendo útil para prototipos de fin de semana, para validar una idea antes de comprometerse con una arquitectura. Pero si construyes algo que va a escalar y va a tener usuarios reales con datos reales, el SDD no es opcional.
La pregunta ya no es si usar agentes, sino si tienes la infraestructura para hacerlo sin romper cosas.